
クラウドワークス Advent Calendar 2021 の 23日目の記事を担当させていただきます @bayashi_ok です。
普段はSREチームに所属しながら、最近は他チームも兼任しており日々様々な事に挑戦中です。
今回は、2021年 SREチームでやったこと の中にも含まれているRedashのバージョンアップの詳細をお話しできればと思います。
クラウドワークス のデータ分析事情
クラウドワークスではデータ分析基盤として古くからRedashを使用しており、長らくversion 4で動き続けていました。
しかしクラウドワークスのRedashは以下のような技術的・組織的課題を抱えておりました。
課題1. 独自実装による魔改造
クラウドワークスのRedashはOSSのものとは違い以下のような独自実装をしていました。
この中で一番重要になってくるのがGoogleスプレッドシート連携です。
これはRedashのクエリ実行結果をスプレッドシートに連携できるという機能です。
簡単に機能紹介をすると、クエリを作成・保存した後に、「Refresh Schedule」の横のリンクをクリックすると、Spreadsheet URL 欄にエクスポート先のSpreadsheetのURLを指定できるようになっています。
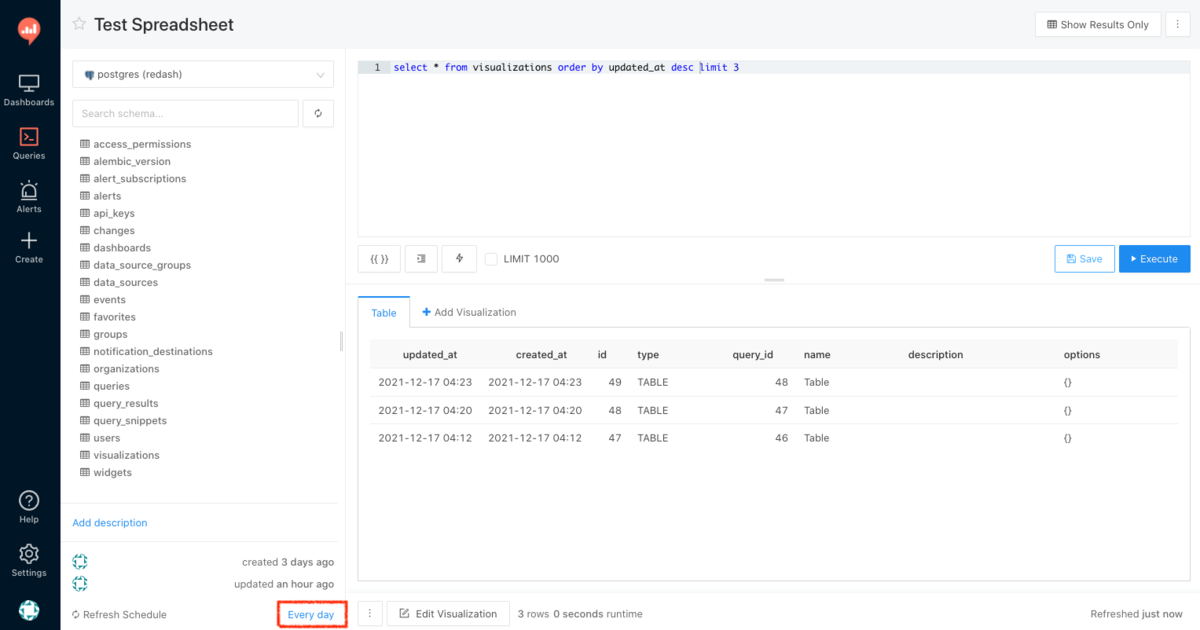
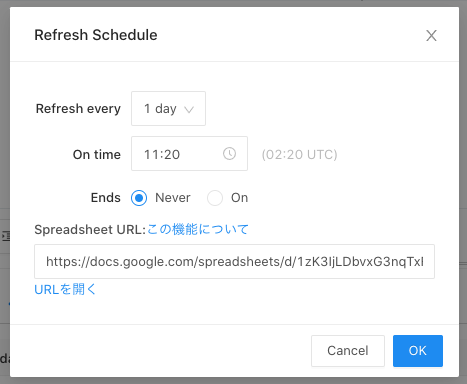
スケジュール実行を行うと、以下のように対象のスプレッドシートに実行結果が反映されるようになっています。

この独自機能はかなり活用され重宝されていましたが、以下のような問題点もありました。
課題2. 担当者不在による無人化
Redash自体はOSSのため誰でも利用できるのですが、独自実装部分においては、実装者が退職した結果、Redashもいわゆる無人化システムの一つとなっていました。
引き継ぎも行われたらしいですが、時代とともに変化し数々の成長を遂げてきたRedashは、全てを引き継ぐ事は難しく、今や中身は誰もわからないという状況でした。
Python2 EOL に伴う対応の必要性
こう言った状況の中、これまでは何事もなく動き続けていたのですが、月日が経つにつれ問題が出てきました。 それがPython2のEOLです。
Python2は2020年4月にメンテナンスが終了してしまったため、このまま放置し続けると、壊れた場合の修正が困難になります。
Redashを管理しているリポジトリでは、CIの中でdocker buildをデイリーで回しているのですが、使用しているモジュールのPython2サポートが切られた影響でビルドエラーが発生し、都度修正を行わないといけないという実害も出てきました。
万が一ビルドエラーが解消できなくなった場合は、
- 動いているDockerイメージを大事に使っていくか
- Redashが依存しているライブラリのバージョンを固定するか
の対応でしのげる可能性もありますが、それもいつまで保つかはわかりません。 メンテナンスが終了しているバージョンのライブラリが、今後も配信され続ける保証はないからです。
これらを強く内部に発信していた結果、プロジェクトが動き出しました。
データ分析基盤対応方針
検討案については大きく分けて以下の通りです。
A. SaaSの利用 (redash.io)
B. 社内にて、新たに素のRedashのサーバを構築する
C. 社内にて、現在の機能を持ったRedashサーバを構築する
D. Redash以外の分析基盤に移行する
A,B,Dは独自改修部分をどのように担保するか、今後の管理をどうしていくかと言う観点からC.の現機能を持ったままPython3対応を行えるようにするという方針となりました。
Python3対応のRedashについては以下で議論され、次のリリースを計画している旨のIssueが出ていました。
プロジェクトは2020年10月頃に発足し始めており、6月にはすでにPython3対応のRedash v9.0.0-betaが出ていたことから、betaがとれる頃にはアップデートを行えるように準備する必要がありました。 そして本格的にチーム体制が組まれたのは年を明けた2021年1月で、私自身もこの頃からインフラ側メインで入るようになりました。
ちなみにA.のredash.ioは、2021年の11月30日を以ってEOLを迎えており、この選択を取った場合更なる移行が待っていることになったので、結果的に選ばなくてよかったと感じました。
Redashのアップデートに向けて
まず最初に行ったのはRedashへの理解です。
Redashという存在は知っていましたが、これまで触ったことがなかったので、どのように動いていて何ができるのか、加えてクラウドワークス上の構成も理解する必要がありました。
クラウドワークスのRedashは上で紹介した独自実装とともにRedashのmulti_orgという機能も使用していました。
multi_org機能について簡単に説明をすると、一つのRedashクラスター内で複数のorgをサブディレクトリ毎で立てれるため、都度Redashクラスターを増やさずにチームやサービス毎でRedashを使用できるというものです。
@ariarijpさんのスライドで詳しい内容が紹介されているので、知りたい方は是非こちらをご覧ください。
これらを踏まえた上で、クラウドワークスのRedashを含めた構成図はこのような状態でした。
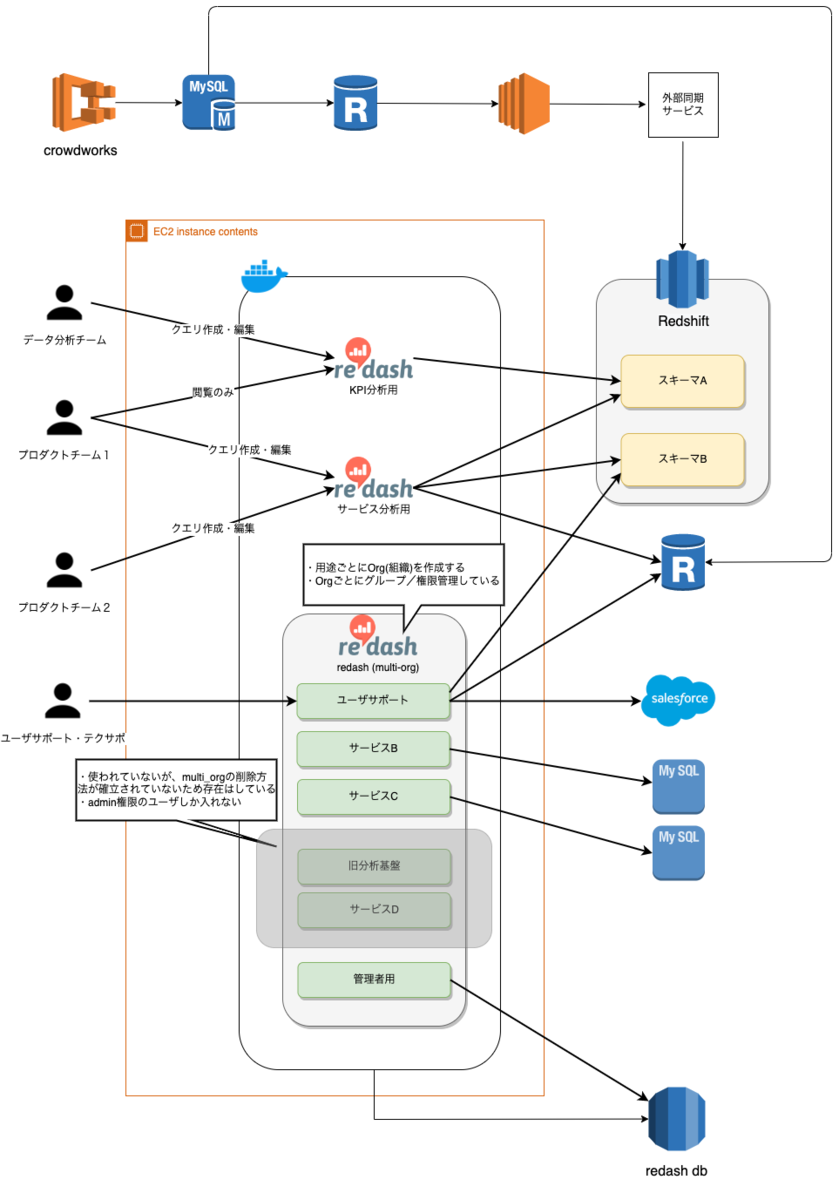
概要をまとめると以下の通りです。
- サーバ(EC2 Instance) は同一のものに、3つのRedashアプリケーションが載っている
- これら3つのRedashアプリケーションは、同一のRDS(PostgreSQL)に接続されており、ユーザ/databaseが分離されている
この3つのアプリケーションの中の一つが先ほど紹介したmulti_org機能で動いており、中でさらに細分化されているため、EC2サーバの中では5,6個のサービスが動いていることになりました。
そしてmulti_orgはその特性から、他のサービスチームも使用しているという状態でした。
さらにmulti_orgについては、テーブル構造的にmulti_org内で持っているデータが共有テーブルに格納されているため、完全に削除するには詳しい調査が必要になってくるので、一度立ち上げると削除しにくいという特性を持っていることもわかりました。
これだけでもうお腹いっぱいだったのですが、他にも考えないといけないことがありました。
無法地帯のクエリ達
実際にRedashの中を見てみるとさらにカヲスな状態になっていました。
- 作ったまま無残に放置されているクエリの数々
- 見ていないのにスケジューリング実行され動き続けているクエリの数々
- 壊れたまま放置されているクエリの数々
- 今現在使っているクエリの数々
- その中でも古くから動いていて消えるとヤバいクエリの数々
色んな負の遺産や、重要なクエリなどが随所に散りばめられておりクエリ総数は 約1万5000件 にも膨れ上がっていました。
さらにスプレッドシート連携の利便性からスプレッドシートのみを参照しているところもあり、普段Redashを触る人はさらに限られている可能性があり無闇に削除もできませんでした。
現状このままアップデートしてしまうと
- 何が必要で何が必要でないクエリか
- 何が動いていて何が動いていなかったクエリか
がわからなくなります。 そのためバージョンアップ作業と並行しクエリ整理も進めていくことになりました。
Redashクエリ整理施策
クエリ整理については以下方法で整理を行いました。
- RedashのDBからアーカイブされていないクエリ一覧を抽出し、スプレットシートに落とし込み使用状況の有無を各部門にチェックしてもらう
- v 5から追加されたRedashのタグ機能を使い、必要なクエリに特定のタグをつけてもらう
最終的にはこれらをmergeしてRedashのDBに対してアーカイブを行いました(と言っても複数のアプリケーションに分かれているのでこれも何回かに分けて実施)。
この作業によってなんと約2/3の 約1万件クエリ がアーカイブされることになりました。
塵も積もれば恐ろしい限りです笑
この中にはもちろんスケジュール実行されているクエリも含まれていたため、 Redashがクエリで参照していたRedshiftのCPU使用率が、80%ほどから60%を切るまで減らすことができました。
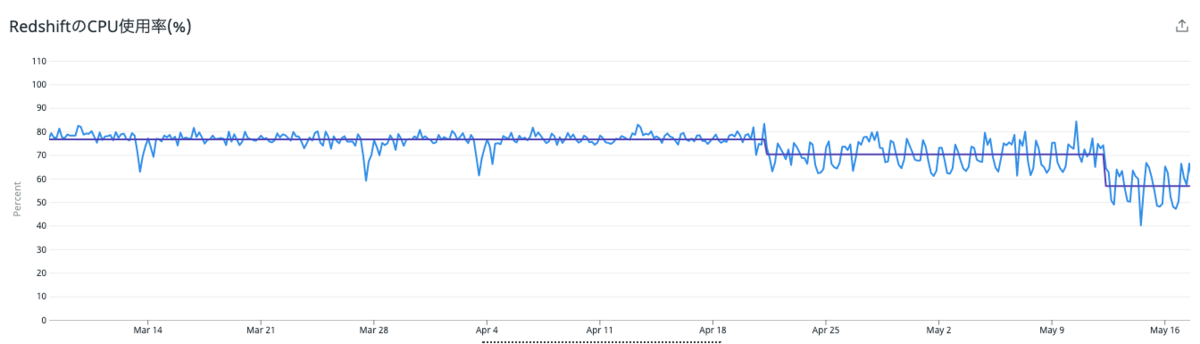
なお、この後、別施策として外部同期サービスをAWSのDatabase Migration Serviceに移行する施策を行った影響で、CPU使用率はまた80%ほどに戻ってしまいました笑 ただクエリ整理をしていなかった場合は100%になっていたことから、スペックアップの検討も必要になっていた可能性もあり、この時点で負荷を減らせたことはかなりよかったです。
※Database Migration Service移行の詳細については以下をご覧ください。
Redashアップデート作業
さて、ようやく本題のRedashアップデートの話です。
と思いきや、またまた考慮しなくてはいけないことがありました笑
作業時間の確保
Redashは歴史を経て今現在いつ誰がどのように使っているか把握することが難しい状況でした。 もし作業中に必要なクエリが実行ができなかった場合、業務に影響が出る可能性もありました。
人の少ない休日の方が良いのではとも思いましたが、休日にアップデートして何かあった場合、担当者が気づきにくいというデメリットもあり、最終的には日中での作業の方が良いと考えました。
そのため、まずは社員に止めてはいけなさそうな時間帯のヒアリングを行いました。
担当チームによってはかなり長い時間、Redashを必要としているチームもあり、改めてRedashの今時点での必要性を感じられるとともに、全体を俯瞰して一番作業しやすようなところを探し出し、個別に調整を行いこの時間であれば大丈夫という合意を取ることができました。
※実際にまとめた集計表

Redashアップデートに向けての取り組み
アップデートを行うにあたり検証環境の準備も必要でした。
当Redashの開発環境は存在していたのですが本番環境と同じような構成にはなっておらず、通常のRedashとmulti_org用のRedashが申し訳程度においてあるだけで、中のデータソースに関しても分析用DBの整備は行われていなかったため、本番相当のデータを使用した上で動作に問題がないかを確認する必要がありました。
そのため本番用のRedashとRedshiftをバックアップから復元し同じような検証環境を一時的に作成し重要なクエリの動作が問題ないかを最低限確認してもらうようにテストを行いました。
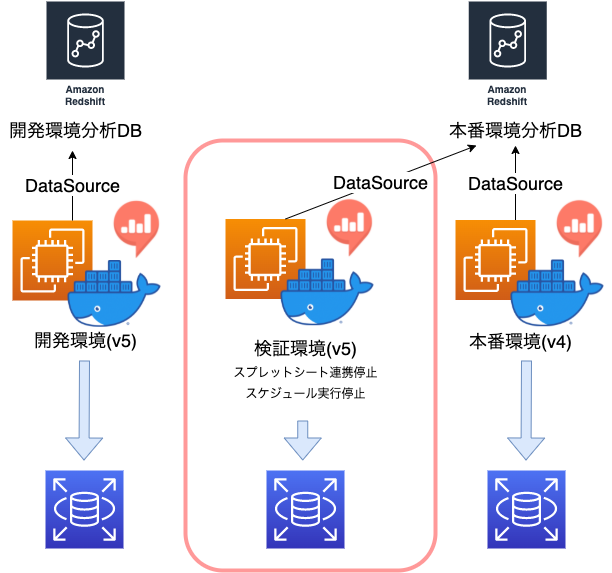
またここで気を付けておかないといけないのが、バックアップから復元したRedshiftが古いデータのままスプレッドシート連携をしてしまい、データの齟齬が起きないかでした。
幸いスプレッドシート連携は環境変数での制御ができる状態であったため、スケジュール実行とスプレッドシート連携の機能を停止した上で本番相当の検証サーバを起動する必要があり、作業自体は容易なものですがかなり緊張しました。
そんなこんなで、検討や考慮をしないといけないことは多々あったのですが、なんとか無事v5へのアップデートを行いました。
v5→v8へのアップデートは検証環境は使わず、開発環境でのアップデート確認と最低限の動作確認を行ったのち時期を少しずらしながら1バージョンずつアップデートを行いました。
アップデート後、小さな問い合わせはあれど無事アップデートも完了し、終えることができました。 念のため、事前に各アップデートに伴う変更点や機能追加部分も説明資料として作っていたのが功を制したのかなと思っています。
Redash v10の話
そして本来の目的であるRedashのPython3対応については、v9はBeta版のまま2021年10月に「Redash v10」が正式なPython3対応版としてリリースされました。
※2021年12月現在の最新はv10.1.0となります。
今回のv10ではPythonも含め以下の変更が入り完全に刷新されています。
- frontend は Angular から 100% React に変更
- backend の job実行が Celery から RQ(Redis Queue) に変更
- backend が Python 2 から 完全に Python 3 に変更
現状開発環境をv10にアップデートし確認を行なっているのですが、v10で新しく登場した LIMIT 1000 のチェックをつけた状態でクエリを実行すると Last Executed At が更新されずスケジューリング実行が動かなかったり、weeklyのスケジュール実行が動かなかったりと、いくつかバグが出てしまっています。
年内リリースを目標にしていたのですが、これらが既存のバグなのか、独自実装による影響なのか、サーバ設定などによる影響なのかまずは問題点の切り分けを行う必要があり、独自実装による弊害が出てしまっています。
※weeklyが動かない問題においては以下Issueがありました。
そんなこんなで今現在も絶賛bugfix対応中ですが、おそらく来年初め頃には本番リリースを迎えられると思います。
その中で、今現在まで自分がひっかかってしまった部分を書いておこうと思います。
サーバのスペックアップが必要(な場合もある)
local環境での検証が済み、開発環境のRedashをv8からv10にアップデートし起動したのですが、Redashにつながらないという現象が起きました。
クラウドワークスのRedashは複数アプリケーションが載っているため前段にnginxを置いてproxyさせているのですが、nginxからの接続がtimeoutしているようでした。
nginxのログを見ると499エラーというnginxの独自エラーコードを返していて、もしかしてスペックが足りないのではという憶測のもと元々t3.mediumだったEC2のインスタンスタイプをt3.largeにあげたところ無事起動することができました。
対応後Issueを見ているとv10はv8,v9と比較してメモリ消費が多いというコメントを見つけました。
DataSourceアイコンが読み込まれない
アップデート後、以下のようにDataSourceのアイコンが読み込まれない現象がおきました。

調査の結果、これはmulti_org機能を使っている場合のみ発生する現象であることがわかり、proxyとして使用しているnginxに設定を追加する必要がありました。
Issueを見ると同じような現象になっている人がいたのでこちらと同様の設定を追加しました。
QUEUESの環境変数
当たり前なんですが今回backend の job実行が Celery から RQ(Redis Queue) に変更したことも含め、QUEUESの環境変数をきちんと変更しておかないと以下のような現象が起きRedashが正しく動きませんでした。
- スケジュール実行が動かない
- クエリ実行はできるがスキーマ一覧が読み込まれない
- default queueがどんどん溜まっていく
- メール送信機能が使えない
- SystemStatusのOutdated Queries 画面が開けない
ドキュメントを事前にきちんと読んでおくことは大事ですね。
整ったドキュメントは今現在なさそうでしたが、QUEUESの主な用途としては以下のようになるかと思います。
- queries::クエリ実行のため必要
- periodic:入れておかないと定期実行処理が動かない
- schemas:入れておかないとスキーマ一覧読み込みが動かない
- default:入れておかないとdefault queueが溜まっていく
- scheduled_queries::スケジュールクエリ実行のため必要
- email:入れておかないとメールが送られない
残課題
今回のv10アップデートはv8アップデートの時とは違い、以下対応に伴いかなり負担が減りました。
- 開発環境が整備されたためクエリ実行確認が容易になった
- クエリの整備を行ったので再度、事前の他部門への調整などをしなくて良くなった
しかし来年無事アップデートを終えたとしても様々な課題があります。
権限周りの整理
クラウドワークスのRedashは独自実装によりGoogleGroupと連携され、対象のグループに追加した人に権限を付与する仕組みをとっています。
これらの仕組みから個人情報の有無や、使用できるDataSourceなどに制限をかけているのですが、組織の規模の拡大に伴い、アクセス権限の細分化を進めていく必要があります。
Redashに依存したバッチがちらほら
クエリ一覧を見ていて驚いたのですが、分析用として利用者に提供しているRedashですが、分析データをもとにメインの業務処理を行なっており、Redashが動かなくなるとSPoFになるものが存在していました。
これらを適切な形に直していく必要があります。
データ分析基盤チームを作る
これがいちばんの重要事項です。
今現在Redashはインフラ面をSREが見ている程度で、あとの使い方はチームごとに任せている状態です。
クラウドワークスは他社と比べると非エンジニアでもSQLを書ける人材が多く大変素晴らしいのですが、長年の運用も相まって古くからのクエリがいくつも動き続けており、取得データの有用性などの価値判断が行いにくくなっているのではと感じています。
また分析用のDBであるRedshiftから派生するデータマートもいくつか存在し、これらも無人化が進んでおり、管理体制の整備が必要になってきます。
今回の対応に関しても恒久的には、データ分析基盤対応方針の中にあった、D. Redash以外の分析基盤に移行する の検討と対応をした上で、きちんとサービスの価値提供を行える基盤作りを行なっていく必要があると考えています。
それらを押し進めていくためにもデータ分析基盤チームの誕生が望まれます。
そういうわけで私達と一緒に1からデータ分析基盤を作っていきたいというエンジニアを絶賛募集しております! データ分析基盤はまだチームとしても存在していない状況ですが、クラウドワークスでは時代が経ち様々な負債を抱えたシステムを改善していこうというチームも立ち上がりました。
興味がある方やお話を聞きたいという方は是非DMやリンクページからの応募をお願いします。