
概要
こんにちは。クラウドワークス SREチームの@kangaechuです。最近好きなラジオ番組は空気階段の踊り場です。
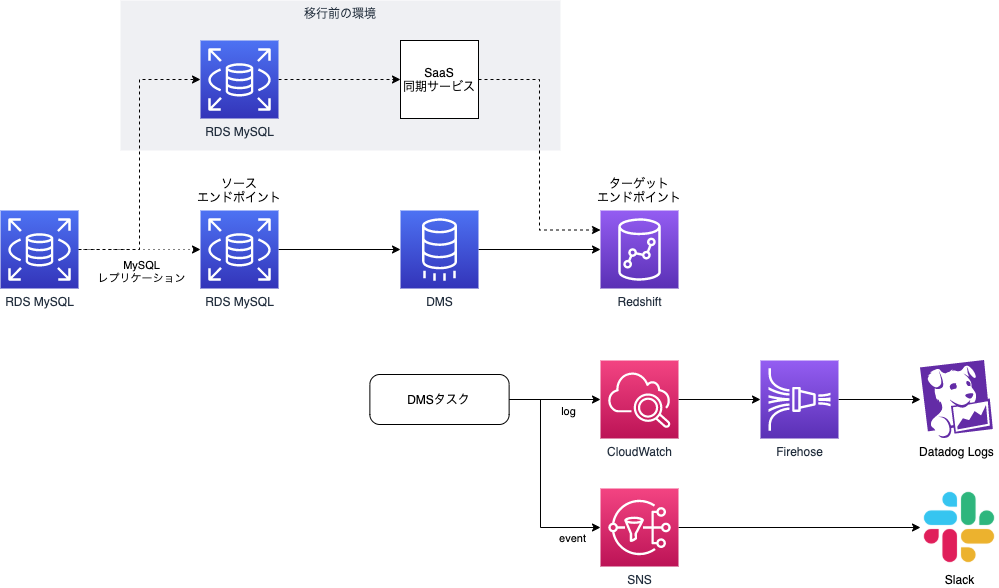
企業にとってデータは非常に重要です。さまざまなデータを組み合わせて分析を行うことにより、ユーザをより深く知ることができ、それによりサービスやビジネスモデルを継続的に変革することが可能になります。 クラウドワークスでも同様に、施策やマーケティング、新サービスの開発など、さまざまな取り組みの源泉としてデータを活用しています。 crowdworks.jpではマスタデータベースにAWS RDSで稼働するMySQLを使用し、分析系のデータベースにはAmazon Redshiftを使用しています。Redshiftに同期されたテーブルは約270テーブル、レコードにして約30億件あり、1か月に1.5億件のレコードが同期されています。 今回はMySQLからRedshiftへの同期の仕組みをAWS DMS (Database Migration Service)を使用して再構築しました。 この記事ではDMS移行の手順とTipsについて紹介します。
背景(なぜやったか)
クラウドワークスではMySQLからRedshiftへの同期を2014年から実施しています(結構古くから使ってますね)。 同期にはSaaSのサービスを使用し、移行直前の2021年7月まで稼働していました。
サービス利用当初はすぐにデータをRedshiftに同期してデータ分析が始められるというSaaSの手軽さが魅力的でした。しかし、サービスの規模が拡大し、データ基盤の重要性が増すにつれて、以下の問題が出てきました。
オペレーションを自動化したい
同期対象のテーブルを追加する際は、利用していたサービスではWebのコンソールにログインし、ぽちぽちする必要がありました。他のオペレーションを自動化するにつれ、履歴が残らず、コードで管理できない部分に不満を感じるようになりました。
コントロールできる範囲を広げたい
SaaSサービスを使用する場合、利用者側ができることは限られています(SaaSという点で見るとこれは正しいのですが)。 サービスの規模が拡大する中で、データ基盤についても監視やパフォーマンスチューニングなどの運用改善に取り組みたいと考えるようになりました。 SaaSではコントロールできる範囲が限られていたため、DMSへの移行を検討しはじめました。
DMS(Database Migration Service)とは
AWS DMS (Database Migration Service) はデータベースを移行・変換するサービスです。DMSはMySQL、PostgreSQL、Oracle、Microsoft SQL Server、Redshiftなどのさまざまなデータベースに対応しています。同期の方法は全同期と全同期+継続同期が選択できます。 DMSは内部でSQLを変換するため、専用のレプリケーションインスタンスの起動が必要です。DMSに変換元と変換先のデータベースの接続情報を指定するエンドポイントを作成し、どのテーブルをどのように変換するかを指定するタスク定義を作成し、タスク定義をレプリケーションインスタンスに割り振ることでタスクを実行します。
やったこと
このドキュメントは2021/7時点(DMSエンジンバージョン3.4.4)での情報となります。 最新の情報は公式ドキュメントを参照してください。
要件決め
今回のデータベース同期では、以下要件をもとに構築を行いました。
- MySQLからRedshiftへの同期
- MySQLのリードレプリカを作成し、ソースエンドポイントとして指定
- Redshiftには現在同期しているものとは別のスキーマを作成し、現新環境の並行稼働を可能にする
- 同期は全同期+継続同期を使用
- 同期対象のテーブルは移行前と同じテーブルを指定
ドキュメントを読む
まずはDMSのユーザガイドを読み、全体概要を理解しました。
ドキュメントはEC2などのメジャーなサービスと比較すると、まだ成熟していないように見えます。以下の点に注意して読みました。
その後、同期元のレコードの型や設定を元に、同期の際に変化する型が異なることにより、差分が発生するかの調査を行いました。
MySQL 互換データベースの AWS DMS のソースとしての使用には SMALLINT が正常に移行されるかの記述がなかったので、サポートに確認したところ、DMSのINT2にマッピングされるとのことでした。
また、MySQLのFLOATはDMSでREAL(DOUBLE)に変換されるとありますが、ターゲットとしての Amazon Redshift の使用にはREAL(DOUBLE)の記述はなかったので、サポートに確認したところ、REAL(DOUBLE)はREAL8にマッピングされるとのことでした。
結果として、現環境と新環境のDMSとで変換の型に差がないことが確認できました。
影響調査
今回は現環境と新環境でのRedshiftで別のスキーマを使用するため、新環境への切り替え時にはRedshiftを入出力とするオンライン・バッチで指定しているスキーマ名を切り替える必要があります。Redshiftを使用しているオンライン・バッチを洗い出し、設定内容を調査しました。前回 Amazon LinuxのEOLに伴いバッチをサーバレス化しFargateに移行した話でほとんどの処理をFargateに移行した際、ドキュメントや設定値を整理したため、ある程度同じ設定方法で対応できました。
機能検証
次に検証環境でマネジメントコンソールを使用し、MySQLからRedshiftの同期をひととおり試し、DMSを使用したMySQLからRedshiftへの同期ができることを確認しました。
MySQLソースエンドポイントの設定
DMSでは、接続対象のデータベースサーバをエンドポイントとして指定します。 ホスト名・ポート番号・データベース名・ユーザ名・パスワードなどの接続情報を設定するだけの簡単な作業です。
ちょっとハマった点としては、MySQLのSSL設定がありました。
DMSのソースエンドポイントにMySQLサーバの接続情報を指定します。その中でSSL通信を行うかを指定可能です。 AWS Database Migration Service での SSL の使用
RDS(MySQL)でSSL通信を使用する際の証明書の設定はAWSがよしなにやってくれる…のではなく、自分で設定する必要があります。 AWS リージョンの証明書バンドル から対象リージョンの証明書をダウンロードし、DMSの証明書画面でインポートする必要があります。
また、この証明書は自動的に更新されないため、RDSのSSL証明書を更新するタイミングに合わせて更新する必要があります。
RDSで使用している rds-ca-2019 の証明書の期限は2022年6月1日に切れます。更新はお忘れなく(自分もね)。
Redshiftターゲットエンドポイントの設定
次に同期先のRedshiftターゲットエンドポイントを作成しました。
設定可能な値として、同期で使用するS3バケットの設定があります。
DMSでRedshiftを同期先とした場合、DMSは内部的に同期対象のレコードを一時的にS3バケットにcsvで保存し、RedshiftのCOPYコマンドによりS3からRedshiftに登録する処理を行います。 そのため、RedshiftターゲットエンドポイントにはS3バケットとそれに対する権限が必要となります。 S3バケット名はRedshiftを同期先とする場合、デフォルトでは以下のリソースが自動的に生成されます。
この場合、複数のRedshiftエンドポイントを作成した場合、どのS3バケットがどのDMSエンドポイントに紐づいているかを理解するのが難しくなります。また、IAMポリシーではS3バケットdms-*に対する権限を付与しているため、権限の分離ができません。
それを解消するため、Redshiftターゲットエンドポイントには以下のパラメータを指定できます。
- ServiceAccessRoleArn: エンドポイントが持つロールを指定
- BucketName: S3バケットを指定
ちょっとハマった点は、マネジメントコンソールからエンドポイント設定を更新すると ServiceAccessRoleArnが消えます。設定はJSONで記述することで回避しました。
タスク定義の設定
設定はデフォルト、同期対象として1テーブルだけ同期設定を行いました。
タスクを実行し、同期できました。やったね!
異常系テスト
次にMySQLやRedshiftが停止した際にDMSがどのような挙動をするのかのテストを行いました。DMSはマネージドサービスのため、エンドポイントの障害を異常系テストとして確認しました。
リトライの挙動設定
通信障害やデータベース障害の際、DMSはどのような挙動となるのでしょうか。 デフォルトのタスク定義では、エラーが発生するとリトライ処理を行います。リトライの間隔は最初5秒ですが、リトライが失敗するたびに増加します。最終的にリトライ間隔が1,800秒を超過すると、タスクは「失敗」というステータスとなり、介入が必要となります。 これらはタスク定義の以下パラメータにより設定が可能です(括弧内はデフォルト値)。
RecoverableErrorInterval(5): タスクの再開を試みてから次に再開を試みるまでAWS DMSが待機する時間(秒)RecoverableErrorThrottling(true): 有効にすると、再開を試みるたびに、次の試行との間隔を延長するRecoverableErrorCount(-1:制限なし): 環境エラーが発生したときに、タスクの再開を試みる最大回数RecoverableErrorThrottlingMax(1800): DMS がタスクの再開を試みてから次に再開を試みるまで待機する最大時間(秒)TableErrorEscalationPolicy(STOP_TASK): エラーのエスカレーション時に実行するアクション
同期元であるRDSのセキュリティグループの設定を変更し、一時的に接続できない障害状態を作りました。DMSのログを確認しながらリトライの挙動を調査したところ、ドキュメント通りの挙動となりました。
ハマったポイントとしては、「障害→正常→障害」と状態を複数回変更した場合、リトライのカウントがリセットされず、2回目以降のリトライの間隔は5秒より大きい値から始まりました。バグっぽいので修正をリクエストしました。
検証環境での同期
機能検証が完了したので、検証環境で同期対象のテーブルを追加し、初期同期・継続同期が正しく動くことを確認しました。
Terraformによる定義
クラウドワークスではAWS環境をTerraformにより管理しています。DMSのタスク定義をそのまま記述すると冗長となるため、以下のようにテーブル定義を生成しました。
resource "aws_dms_replication_task" "default" {
table_mappings = jsonencode(
{
"rules" : [for table in local.tables : {
rule-id : tostring(index(local.tables, table) + 1)
rule-name : tostring(index(local.tables, table) + 1)
rule-type : "selection"
rule-action : "explicit"
object-locator : { "schema-name" : "schema01", "table-name" : table },
}]
}
)
(省略)
}
locals {
tables = [
# 同期対象のテーブルをリストする
"aaa_table",
"bbb_table",
(省略)
}
監視設計
production環境の構築前に監視設計を行いました。 監視対象は以下の通りです。
ソースエンドポイントとターゲットエンドポイントについては、インフラ関連のメトリクス(CPU使用率・ストレージ使用率など)をDatadogで監視しています。
DMSインスタンスはインフラ関連のメトリクスに加え、以下の観点での監視も追加しました。
- ログ監視(エラー・ワーニング)
- タスクのステータス変更
ログ監視については、300GB/day出力されるログ基盤をFluent Bit + Fargate + NLBで再構築したら、エンジニアの作業効率が上がった と同様に、CloudWatch Logsに出力されたログをSubscription Filters経由でFirehoseに送信し、Datadog LogsからSlackに通知するよう設定を行いました。

タスクのステータス変更についてはSNS経由でEmailを送信し、EmailをSlack連携しています。 ひとまず簡単な形での連携を行いましたが、SlackのEmail連携はクリックしないと本文が読めないため、イマイチです。将来的にはSlackで読みやすい形に整形したいです。
同期遅延については、マスタデータベースに定期的に現在時刻を書き込む処理を実行し、同期先のRedshiftで現在時刻とデータベースから取り出した時刻を比較して同期遅延を求めています。この処理は移行前から構築されていたため、この仕組みを踏襲しました。
また、DatadogにDMSのダッシュボードを作成し、同期状況をモニタリングできるようにしています。

production環境での同期
検証環境でひととおり検証できたので、production環境でも同期を実施しました。 同期前にはRDSインスタンス・DMSインスタンス・Redshiftクラスターを増強し、初期同期にかかる時間を減らすようにしました。 動的にスケールできるのはクラウドの利点ですね。 全テーブルの同期処理は合計で13時間半くらいかかりました。
同期後に同期元のMySQLレプリケーションを停止し、静止した状態でMySQLとRedshiftのテーブルごとの件数を比較しました。 結果として、同期のステータス自体は正常終了となっていたのに、いくつかのテーブルのレコードが欠損していることに気がつきました。
欠損したレコードが同期された時間帯に出力されたメッセージは以下の通りです。
Message : Reading from source endpoint temporary paused as total storage used by swap files exceeded the limit for task: xxxx
メトリクスを確認しましたが、DMSインスタンスでスワップが不足している様子は観察できませんでした。 レコードの欠損が発生した時間帯にはレコード長の長いテーブルを同期していており、このテーブル同期による負荷上昇がレコード欠損の要因となったのではないかという推測を行いました。
そのため、回避策として、以下のことを行いました。
MaxFullLoadSubTasks(全同期時のサブタスク数)を8から4に減らす- レコード長の長いテーブルのみ先行して同期を行い、その後にそれ以外のテーブルを同期する
これにより、エラーが再発することはありませんでした。
エラー時の振る舞い
DMSではエラー時の振る舞いをタスク設定でコントロールできます。たとえばターゲットへの書き込み時にエラーが発生した時の振る舞いはApplyErrorDeletePolicy / ApplyErrorInsertPolicy / ApplyErrorUpdatePolicyで設定でき、指定可能な値は以下の通りです。(Error handling task settings)
IGNORE_RECORD: タスクは継続し、エラーとなったレコードは無効となるLOG_ERROR: タスクは継続し、エラーとなったレコードはログに記録するSUSPEND_TABLE: タスクは継続するが、エラーとなったテーブルはエラー状態となり、同期を停止するSTOP_TASK: タスクを停止する
ApplyErrorDeletePolicyのデフォルトはIGNORE_RECORDのため、意図しないレコードが残るかもしれません。必要であれば設定を変更しましょう。
当初、すべてのエラーの振る舞いにSUSPEND_TABLEを指定していましたが、エラーのたびに同期が停止すると介入が必要となるため、LOG_ERRORに変更しました。
またApplyErrorxxxPolicyに関連するパラメータにBatchApplyEnabledがあります。trueを指定すると、複数のSQLクエリをまとめて実行してくれます。たとえば同じprimary keyに対し、INSERT→DELETEするクエリがあった場合、そのクエリは実行されません。
When BatchApplyEnabled is set to true, AWS DMS generates an error message if a target table has a unique constraint. When BatchApplyEnabled is set to true and AWS DMS encounters a data error from a table with the default error-handling policy, the AWS DMS task switches from batch mode to one-by-one mode for the rest of the tables. To alter this behavior, you can set the "SUSPEND_TABLE" action on the following policies in the "ErrorBehavior" group property of the task settings JSON file:
上記ドキュメントにもある通り、デフォルトの指定であれば、バッチでのApplyに失敗した場合、one-by-oneモードに変更し、残りのクエリを順番で実行します。一度エラーとみなされても救ってくれるということですね。
ApplyErrorDeletePolicyはデフォルトのIGNORE_RECORDからLOG_ERRORに変更したため、この条件を満たさないのでone-by-oneモードに切り替わらないのではと当初考えていました。ただ、実際に試したところApplyErrorDeletePolicy=LOG_ERRORでもone-by-oneモードへの切り替えを確認しました。これは嬉しい誤算でした。
DMSタスクを停止/再開した際に出力される警告メッセージ
production環境でタスクの停止を試したところ、タスクの再開時に以下のメッセージが表示されました(見やすさのため改行しています)。
2021-06-24T00:00:00 [SOURCE_CAPTURE ]W: The given Source Change Position points inside a transaction. Replicate will ignore this transaction and will capture events from the next BEGIN or DDL events. (mysql_endpoint_capture.c:3282)
タスク再開時のポジションがトランザクション中にあるため、そのトランザクションは読み飛ばされたとのことです。これはつらい。 DMS停止の際はトランザクション前までROLLBACKするか、トランザクション終わりまで進めて欲しいです。
しかもこのメッセージ、DMSタスク停止後の再開時にほぼ毎回表示されます。
現在の回避策としては、計画作業でDMSタスクを停止する場合は同期元のMySQLのレプリケーションも停止し、無風の状態にしてからDMSタスクを停止しています。その他メンテナンスウィンドウのタイミングなどでこのメッセージが表示された場合はMySQLのbinlogから影響を受けた可能性のあるレコードを特定し、データ不整合が発生している場合は該当テーブルを再同期して復旧しています。
まとめ
よかったこと
DMSへの移行により、以下の利点を得られました。
- 同期対象のテーブルをTerraformで管理することにより、修正の意図や経緯をGitに残せる
- 同期遅延自体を減らすことができた
旧環境では平常時でも20〜30分程度の同期遅延がありましたが、新環境では2〜3分程度の遅延で同期できています。 また現状DMSレプリケーションインスタンスは1つで、インスタンスタイプはdms.c5.large(multi-az)で十分捌けているので今のところスケーラビリティの不安もなく、ボトルネックはどちらかというと書き込み先のRedshiftです。旧環境で使用していたSaaSは同期レコード数ベースの課金体系でしたが、新環境のDMSはコンピューティングリソースに課金されるので、パフォーマンステストなども気軽にしやすくなりました。
また、データ基盤の知見を得られたのも良い点でした。 データ基盤は一度作成すると誰がどのように使っているかを追うのは難しいです。 現時点での状況整理ができ、ドキュメントにも残せたので、今後データ基盤の整備をする際に役立つと考えています。
将来やりたいこと
DMSへの移行のリリースを優先してしまったため、一部手動でのオペレーションが残ってしまいました。APIなどを活用し、できる限り自動化を進めていきたいです。
今回は作業量が多くスコープに入れることができませんでしたが、RedshiftはRA3インスタンスへの移行をしたいです。なんといってもAQUAで10倍高速は気になります。
また、今回は現状の同期設定をそのまま移行するためスコープ外としましたが、Amazon S3 への DB スナップショットデータのエクスポート も使用したいです。RDSのスナップショットをS3にParquet形式で出力することにより、Redshift spectrumからクエリできます。 すべてのテーブルをニアリアルタイムで同期する必要はないため、鮮度が不要なデータはS3のデータを参照し、鮮度が必要なデータはDMSでの同期を行えるようにしていきたいです。
We're hiring!
クラウドワークスはたのしいよ!みんなはいってね!