これは クラウドワークス アドベントカレンダー 24日目の記事です。前日は 畑中 さんの制作会社出身のデザイナーが事業会社に入って感じた5つの悩み事でした。事業会社とデザイン制作会社の違いから生まれる悩みをどう解決したかが伝わる記事でした。
クラウドワークスSREチームの @kangaechu です。最近はM1 Macを購入しました。M1 Macはアプリケーションの対応状況がまだまだなので、Goをソースからクロスコンパイルするなど、今までやったことがないことができてちょっと楽しいです。でももう少しネイティブのアプリが揃うと嬉しいな。
アドベントカレンダーはSREチームに入ってからの2年間にチームでやってきたことに続き、2つめのエントリとなります。前回の記事で、Docker化したシステムの一つとしてfluentd(ログ基盤)を挙げました。ここではそのログ基盤についての詳細を書いていきます。
クラウドワークスのログ基盤とその課題
クラウドワークスはクライアント70万社、クラウドワーカー300万人を支えるオンライン人材マッチングプラットフォームです。プラットフォームの持続的な改善や障害調査のため、システムが生成するログを適宜保管し、検索ができる必要があります。
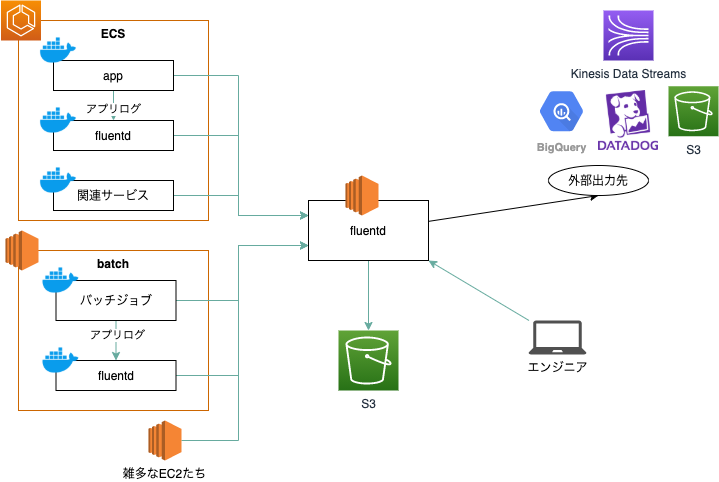
クラウドワークスでは2013年頃にログ基盤を構築しました。fluentdによりログを収集し、そのログをEC2のfluentdサーバに保持し、S3にバックアップする構成です。当初は流量も少なかったですが、成長に伴い、fluentdが一日に処理するログの量は300GBにもなりました。
初期構築から数年が経過し、運用を続けていく上で様々な課題が出てきました。
設定が複雑で、テストもない
新規サービスの監視やメトリクスのDatadog通知など、運用に合わせてログの種類を増やしたり、外部出力先を増やした結果、fluentdの設定ファイルが複雑なものになっていきました。テストについてはServerspecレベルでの単体テストはありましたが、fluentdの設定に対する機能確認テストがなかったため、設定の変更やfluentdのバージョンアップに対する障壁が高く、改善が進まない状況でした。
fluentdのバージョンが0.12系で古い
先ほど述べたとおり、バージョンをあげる心理的負荷が高かったため、バージョンがv0.12系で止まっていました。現在の最新はv1.11です。 また、v0.12以前とv0.14以降との間にはプラグインの互換性がないため、プラグインを更新する必要があります。更新したプラグインの検証や、更新されなくなったプラグインの場合は再実装などの必要性があることを考えると、バージョンアップにかかる負担は軽くありませんでした。
ログの検索がgrepでつらい
ログの検索のしくみがないため、エンジニアはfluentdサーバやS3に保存されたログをgrepする必要がありました。対象のログを探索するためにはsed/awk/perlを使ったワンライナーの腕が試される、90年代を彷彿とさせる作りとなっていました。検索するエンジニアの負荷が高いので、検索する割合の高い一部ログはBigQueryに流し、検索できるようにしていましたが、これもシステムの複雑性を高める原因となっていました。
fluentdがシングル構成のため、SPOF
fluentdで構築されたログ基盤はシングル構成であったため、SPOFでした。fluentdのサーバが止まると各サービスがログを送信できなくなり、サービス継続に支障がでる構成でした。
Chefで構築されている
構築当初はホットなテクノロジーであったChefですが、コンテナ化のあおりをうけインフラエンジニアのスキルセットからChefが外れたように思われます。 クラウドワークスのSREもDockerを触ったことがあるが、Chefを触った経験のないメンバもいるため、Chefを廃止し、Dockerに移行したいと考えるようになりました。
これらの課題を解消するため、新しいログ基盤を構築することになりました。
やったこと
現状の整理
まずやったことは現状の整理です。fluentdの設定ファイルを以下のポイントで整理しました。
- 入力
- 出力
- プラグイン
整理したところ、入力: 125種類、出力: 7種類、プラグイン: 13種類でした。この中には今使われていない設定の残骸も含まれています。 設定ファイルが複雑なのもうなずけますね。
ログの整理
次に行ったことは対象のログを減らすことです。 現在の設定のまま単純にログ基盤を移行するのでは、設定の複雑さという課題を解決できません。また、一般的なSaaSのログ基盤ではログのデータ量による課金が多く見受けられるため、データ量を減らすことはコスト削減につながります。 そのため、入力・出力・プラグインの数を減らすことは重要です。 そのため、新環境を構築する前に、fluentdの環境で不要なログを減らしました。
ログの要否確認のため、整理した結果をもとに各チームに「このログ本当に要ります?」と確認して回りました。不要と判断されたログについてはアプリケーションのコードを修正し、出力部分を削除しました。
また、fluentdはさまざまなEC2サーバのログも収集していました。これらのログをCloudWatch Logsに移行しました。CloudWatch LogsはAWSのログ保存・監視・検索サービスです。AWS内であれば、ネットワークの構成を気にせずにログの保存が可能です。 しかし、CloudWatch Logsはデータの取り込み料金が高いという欠点があります。 そのため、ログの流量が少ないサーバログについては、出力先をCloudWatch Logsに変更しました。
これらの作業により、出力されるログの総量は一日あたり300GBだったものを、140GBまで減らすことができました。
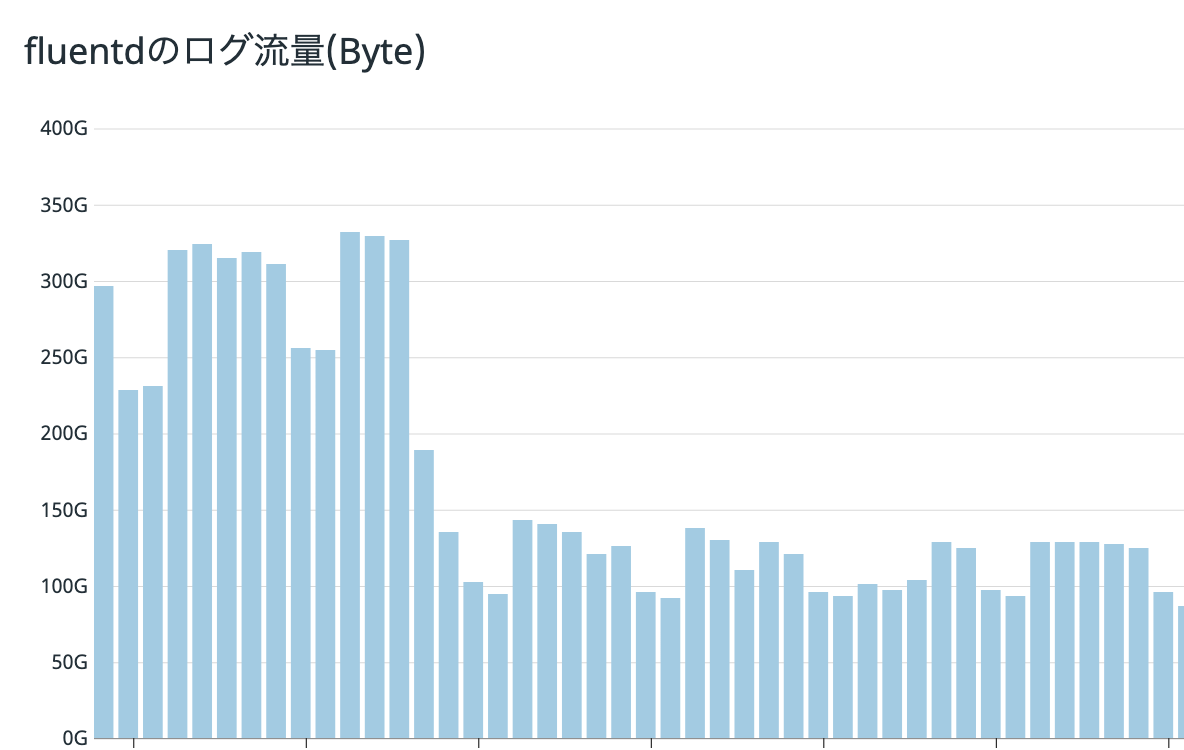
また、結果としてfluentdの設定を
と大幅に減らすことができました。
方針検討
ログ集約の方法について、SaaSなどを含めた方針検討を行いました。結果として以下の理由により、AWS上に自前で運用することにしました。
また、AWS環境でのログ基盤構築として、ざっくりと以下の構成を検討しました。
- Firehoseでログ集約
- 集約したログをS3に保管
- Athenaでクエリ(BigQueryを廃止)
ログ基盤の構成はFluent Bit による集中コンテナロギングを参考にしました。
PoC
方針検討をもとに、1種類のログに対してログの入力から検索までを行うPoC環境を作成しました。
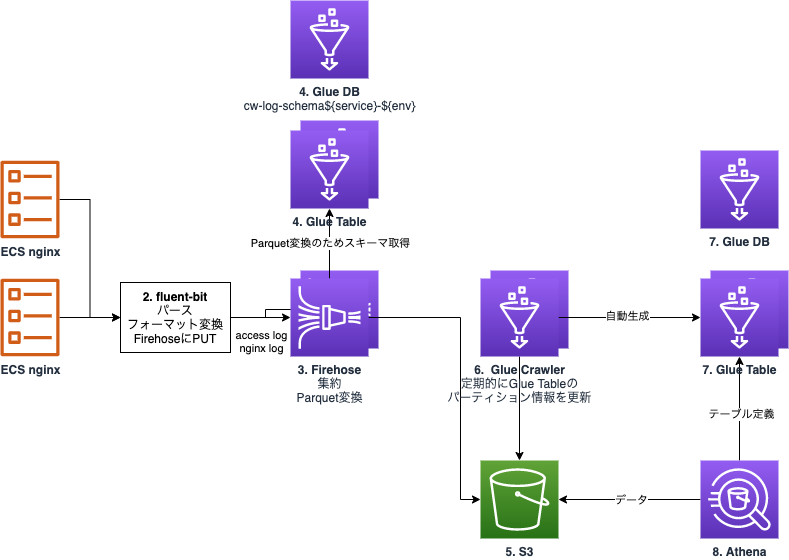
AWS資料との差異は以下の通りです。
- Firehoseで入力されたレコードを直接保存するのではなく、検索速度とコスト削減を見越したParquet形式での保存
- Athenaでの検索のため、Glue Table / Glue Crawlerの追加(最終的な構成ではPartition Projectionを採用)
- Terraformによる構築
検証のポイントは、以下の2点です。
- Fluent BitでFirehoseを経由してS3にログの保管ができるか
- Athenaで検索が行えるか
特にFluent Bitは初めて使用したので、fluentdとの設定ファイルとの差異を意識しながら書きましたが、特につまることはなく記述ができました。 また、Athenaの検索もログ出力から5〜10分程度でクエリができました。
設計
PoCを受けて、設計を再度行いました。
構築中に修正を加え、最終的にはこのようになりました。

- ログはFluentd Forward ProtocolでFluent Bitに送信する。ECSやEC2のDockerの標準出力/エラー出力はDockerのfluentd logging driverを使用、Railsアプリ内部の独自のログはfluent-logger gemを使用する
- Fluent BitはDockerコンテナとしてデプロイし、ECS Fargateでクラスタ化、NLBで負荷分散と冗長化
- Fluent Bitはforward input pluginで受信し、入力されたログのタグと設定に応じ、指定された出力先(Kinesis Data Streams / Kinesis Firehose)にログを送る
- FirehoseはParquet形式でログをS3に保存する
- エンジニアはAthenaからSQLでログ検索を行う
Fluent Bitを採用した理由は、使用するリソースの低減や速度の向上が見込めることによるものです。Rubyで書かれたfluentdと比較すると、Cで書かれているFluent Bitは少ないリソースで大量のログを捌くことができそうです。 また、Fluent Bitは本体にAWS/Azure/GCPなどのクラウドプロバイダや、ElasticsearchやKafkaなどのプラグインが同梱されています。 さらにプラグインを追加したい場合はGoやLuaによる出力プラグインの作成が可能です。 今回はKinesis Data stream とKinesis Firehoseへの出力があったので、AWSが提供しているaws/aws-for-fluent-bit を使用しています。Kinesis Data stream とKinesis Firehoseへの出力プラグインはFluent Bit 1.6から本家で実装されているので、現在は追加のプラグインは不要です。
NLBで受け、Fargate経由でFirehoseに流す構成は、SPOFを避け、動的なスケール変更を容易にするためです。また、FirehoseではS3への出力時に出力する形式を指定することができます。今回はParquetでの出力を指定しています。Parquetは列指向のフォーマットで、特定の列を選択・集計するような分析用途でよく使われています。特定の時間帯の特定のユーザのログを取得する際に向いているフォーマットであると考え、Parquetを採用しました。
S3に保存し、Athenaでクエリする構成とした理由は、運用のコストを最小限にしたいという理由からです。ログを検索するのであれば、Elasticsearchなどを使用する構成もありますが、Elasticsearchのバージョンアップやログストレージの管理などの負担が大きいため、自分たちで管理しなければならないリソースができるだけ少ない構成を採用しました。S3に保存し、Athenaでクエリする構成であれば、AWSマネージドのサービスのため、運用コストは下がります。また、S3の料金は安く、Athenaはスキャンしたデータ量による課金のため、検索があまり多くないケースであれば費用も多くかかりません。また、ログの保管形式をParquetにしたことにより、スキャンする列を絞ることでより費用を抑えることが可能になりました。 以前は検索を容易にするため、一部ログをBigQueryに流していましたが、Athenaで検索することによりこれらの処理も不要となりました。
実装
最近のDocker化の流れに合わせ、Fluent BitもDockerで構築しました。 aws/aws-for-fluent-bit をベースイメージとし、そこに設定ファイルを追加するスタイルです。 処理するログのバリエーションを減らしたことにより、設定ファイルをシンプルに保つことができ、見通しがよくなりました。 また、設定ファイルはテンプレートと環境ごとのパラメータファイルを準備し、ERBでrenderすることにより、環境差異を埋めた設定ファイルを生成しています。 これにより、最終的な成果物である設定ファイルに変数参照や条件分岐がなくなり、読みやすさの向上につながりました。
テスト
Fluent Bitの設定が正しいか、バージョンアップ時に壊れていないかを確認するため、テストを追加しました。 テスト環境はDockerで構築し、Docker Composeで実行します。
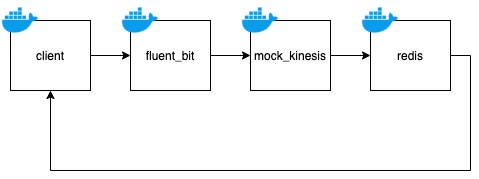
処理手順は以下の通りです。
- clientがfluent_bitコンテナにログを投げる
- fluent_bitコンテナで動くFluent Bitは設定ファイルに記述した宛先(mock_kinesis)にログを出力する
- mock_kinesisはKinesis Data Stream / Kinesis FirehoseをモックしたHTTPサーバ。mock_kinesisはログをredisに投げる
- clientはredisの値を読み取り、期待したテスト結果とを比較する
このテストをGitHub Actionsに組み込み、Pull Request時にテストが動くように設定しました。これにより、エンジニアは安心して設定を変更できるようになりました。 また、Dependabotを組み込んでいるため、Fluent Bitのバージョンアップにかんたんに追従できるようになりました。
また、リリースには間に合いませんでしたが、Fluent Bitの設定ファイルの構文チェックをするオプション(Apacheでいうapachectl configtest)がなかったので、Issueとプルリクエストを作成しました。プルリクエストは先日無事にマージされ、次のバージョンあたりで取り込まれるはずです。(みんなが使うプロダクトでマージされるとテンションが上がりますね!)
デプロイ
デプロイも同様にGitHub Actionsに組み込みました。対象ブランチへのマージの際に起動し、各環境へのデプロイが自動的に行われるようにしました。 これにより、GitHubの操作のみでデプロイまで完結できました。
監視
Fluent Bitが正しく動いているかを確認するため、監視設定を追加しています。 監視の対象は以下の通りです。
- Fargateで動くFluent Bitコンテナのタスク数
- Fluent Bitのログ(Error/Warning)
- Fluent Bitコンテナのログ流量
- Kinesis Data Stream / Firehoseのログ流量
Fargateで動くFluent Bitコンテナのタスク数は、Datadogのmonitoringを使用し、タスク数が閾値を下回ったらSlackに通知する設定を追加しています。 Fluent Bitのログ(Error/Warning)は、Fluent Bitのコンテナ自身のログはCloudWatch Logsに出力しており、これを通知する条件を細かく指定してSlackに通知しようとするとLambdaで作り込みが必要そうでした。メトリクスの監視はDatadogに集約しているので、ログの監視もDatadog Logsに投げる構成にしました。

- Fluent BitコンテナがログをCloudWatch Logsへ出力
- CloudWatch LogsにSubscription Filtersを定義し、CloudWatch LogsからFirehoseへ流す
- FirehoseからDatadogへ流す
- DatadogでMonitor経由でSlackへ通知
CloudWatch LogsからDatadog Logsにログを投げるのには、7月に追加されたFirehoseのDatadogへのデータ配信機能を使用しました。 https://aws.amazon.com/jp/about-aws/whats-new/2020/07/amazon-kinesis-data-firehose-now-supports-data-delivery-to-datadog/ https://www.datadoghq.com/ja/blog/stream-logs-with-kinesis-firehose-and-datadog/ これにより、CloudWatch Logsに出力したFuent BitのログをKinesis Firehose経由でDatadog Logsに送信できました。
Fluent Bitコンテナのログ流量は、Fluent BitのPrometheusエンドポイント を使用し、Fluent Bitコンテナのサイドカーとして定義したDatadog Agent経由でDatadogに投げる構成としました。
Tipsとして、メトリクスの名前付けがあります。
デフォルトでは取得するメトリクスは配列の要素番号しか取得できません。複数のプラグインを使用している場合、どの要素がどの設定に対応しているのかわからず困りました。
Aliasを設定すると、要素と設定の紐付けができるようになります。
[FILTER]
Name modify
Match *.nginx.access_log
Alias modify-nginx-access-log
[FILTER]
Name modify
Match *.nginx.nginx_log
Alias modify-nginx-nginx-log
Kinesis Data Stream / Firehoseのログ流量はDatadogのAWSインテグレーションのメトリクスから取得し、Slackに通知しています。
移行
ログ基盤の移行で一番怖いのがログのロストです。移行完了まではFluent Bitに出力されたログをfluentdにも出力していました。これにより、Fluent Bitの設定がミスっていて新ログ基盤にログが保存されていない場合でも、旧ログ基盤にはログ保存されていることが期待できます。
移行は平日の日中帯に実施しました。出力先を少しずつFluent Bit側に切り替え、Fluent Bitにログが送信されることを確認しました。その後、問題がないことを確認してからfluentdへの送信経路を削除しました。
エンジニアへのリリース
ようやくエンジニアへのリリースとなりました。ドキュメントを準備し、リリース完了 🎉 クエリ速度も速く、SQLによる検索ができるようになったため、エンジニアの検索体験も爆上がりで、作業効率も上がりました。
まとめ
ログ基盤という性質上、様々なシステムと連携しており、これを更新するのは至難の技でしたが、構築前に挙げた課題を全て解決することができました。
- 設定が複雑で、テストもない → 管理対象を減らしたことによりシンプルな設定となった。またテストを書くことでバージョンアップへの障壁を減らすことができた
- fluentdのバージョンが0.12系で古い → Fluent Bitの最新版を使用。また、CI/CDを整備したことにより、Dependabotのバージョンアップ通知のプルリクエストをマージするだけで最新版に更新できるようになった。
- ログの検索がgrepでつらい → AthenaによるSQLでの検索ができるようになり、エンジニアの体験をあげることができた
- fluentdがSPOF → Fluent Bitの前段にNLBを配置することにより、SPOFではなくなった。
- Chefで構築されている → Fargate+Dockerの構成のため、Chefが不要となった。
リリース後は特に障害もなく動いているので、一安心です。
反省点としては、絶賛開発中のFluent Bitではなく、枯れたfluentdの最新版を使えばもう少し楽だったかなと思っています。 あと、構築中にFLuent Bitのドキュメント抜け漏れをいくつか発見していたのですが、ちゃんとメモっておくのを忘れてしまいました。次に見つけたらコントリビューションしていきたいですね。
最終日のアドベントカレンダーを飾るのは @t-okibayashi さんの入社エントリーです。 ご期待ください!