
この記事は クラウドワークス グループ Advent Calendar 2025 シリーズ3 6日目の記事です。 crowdworks.jp SREチームの田中 (kangaechu) です。
先日、crowdworks.jpで利用しているAmazon Aurora (MySQL互換) において、History List Length が異常な増加を示す事象が発生しました。 一見するとデータベースの書き込み負荷が高いように見えますが、調査を進めると、意外にもリーダーインスタンスで実行されていた長時間のSELECTクエリが原因であることが判明しました。 今回は、その検知から原因特定、解決に至るまでのプロセスと、Aurora特有の仕組みについて共有します。
History List Lengthとは?
調査内容に入る前に、今回の主役である History List Lengthについて簡単におさらいします。 Auroraは、MVCC(Multi-Version Concurrency Control) という仕組みを採用しており、データの更新や削除が行われても、即座に古いデータを消去するわけではありません。 他のトランザクションが一貫性のある読み取りを行えるよう、古いバージョンのデータを Undo Log として一時的に保持します。
通常、不要になったUndo Logはバックグラウンドプロセスによって定期的に削除されます。 しかし、古いデータを参照し続けているトランザクション が一つでも存在すると、それ以降のすべての変更履歴を削除できずに保持し続ける必要があります。
History List Length とは、パージされずに溜まっている変更履歴のリストの長さを示す指標です。
History List Lengthが増加した場合の影響
この数値が極端に増加すると、以下のような悪影響が出ます。
- SELECT性能の低下: 最新のデータから過去のデータを辿る探索コストが増えるため、クエリが遅くなる可能性があります。
- ストレージ容量の圧迫: 不要な履歴データが削除されないため、ストレージ使用量が増加します。
- シャットダウン時間の増加: 再起動時などにUndo Logの処理に時間がかかる場合があります。
事象
Datadogで監視しているAuroraのメトリクスを確認していたところ、この InnoDB History List Length が奇妙な挙動を示していました。
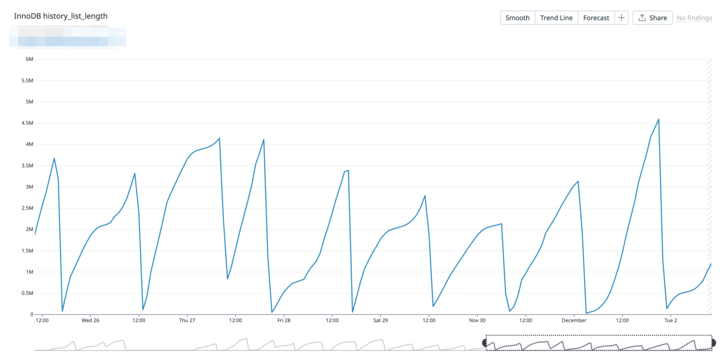
- 周期的な変動: 約18時間かけて上昇し、その後2時間ほどで急降下する動きを繰り返している。
- 傾向の変化: 直近1ヶ月ほどでこの周期性が現れ始め、ここ数週間で常態化していた。
- 最大値:最大で4,500,000と異常な値となっていた
通常であれば低い値で安定するはずのグラフが、毎日規則正しく積み上がっている状態でした。
調査
ライターインスタンス
History List Lengthが増加する最大の原因は、前述の通り長時間実行されているトランザクションです。
まず疑ったのは、ライターインスタンスです。 以下のクエリを実行し、現在進行中のトランザクションを確認しました。
SELECT trx_id, trx_state, trx_started, TIME_TO_SEC(TIMEDIFF(NOW(), trx_started)) AS duration_sec FROM information_schema.innodb_trx ORDER BY trx_started ASC\G
しかし、結果はシロ。 実行中のトランザクションは存在するものの、経過時間は数秒程度。History List Lengthを長時間押し上げ、パージをブロックするようなプロセスは見当たりませんでした。
ドキュメントの参照
Writerに原因がないなら、なぜUndo Logが消えないのか? 調査に行き詰まりかけた時、AWSの公式ドキュメントにある記述が目に留まりました。
Make sure also to look for long-running transactions on read replicas.
The InnoDB history list length increased significantly より引用
ここが盲点でした。Auroraのストレージアーキテクチャは、WriterとReaderで共有されています。 Reader側で古いデータを参照し続けているトランザクションがいると、ストレージシステム全体としてそのバージョンをパージすることができず、History List Lengthが増加し続けるようです。
リーダーインスタンス
すぐにリーダーインスタンスへ接続し、同様に information_schema.innodb_trx を確認しました。
*************************** 1. row *************************** trx_id: 351845327319112 trx_state: RUNNING trx_started: 2025-12-01 13:52:28 duration_sec: 42955
- 経過時間: 約43,000秒(約12時間)
- 実行元: 分析基盤
- 内容: 大規模なテーブルに対する LIKE 中間一致検索
分析基盤から定期実行されていた重たい分析クエリが、終わることなく走り続け、その間ずっとUndo Logの削除をブロックしていたようです。 グラフの「18時間上昇」という周期は、このクエリが実行され、何らかの理由で終了するまでのサイクルと一致していました。
対応
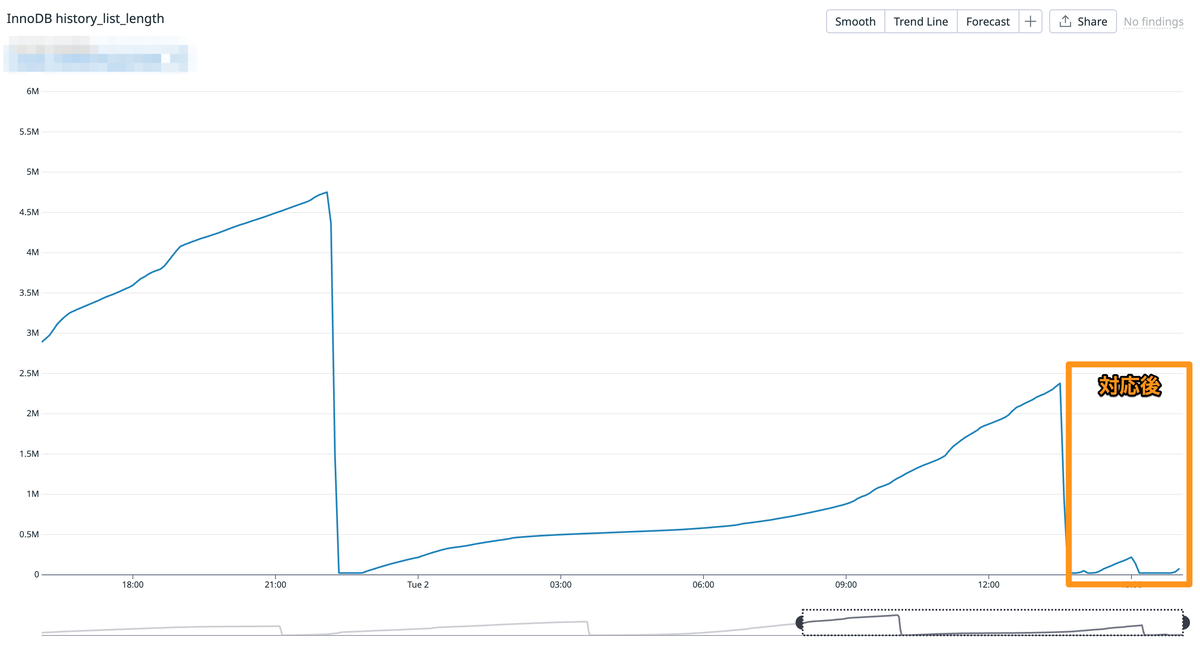
原因が特定できたため、分析基盤のクエリを見直しました。 Datadogのグラフも落ち着きました。
まとめ
今回の対応により、AuroraでHistory List Lengthが発生した場合はリーダーインスタンスも確認する必要があることがわかりました。 また、分析基盤などのBIツールで、意図せず重いクエリがスケジュール実行され続けていないか、クエリの定期的な棚卸しも必要です。
「AuroraのHistory List Lengthが下がらない!」という現象に遭遇した際は、リーダーインスタンスで processlist や information_schema.innodb_trx も確認してみてください。
追記
と意図せず同じ内容の記事を書いていますが、偶然の産物です。 タイミーさんのブログではAWSサポートに確認し、トランザクションの分離レベルにまで踏み込んでいるのでこちらも参考にすると良いかと思います。