
この記事は クラウドワークス Advent Calendar 2023 シリーズ2 の 7日目の記事です。
こんにちは。crowdworks.jp SRE チームの田中(@kangaechu)です。 2023年は生成AI、特にLLM(大規模言語モデル)が盛り上がりを見せた年でした。皆さんもChatGPTやGitHub Copilotなどにより、その恩恵にあずかった1年だったかと思います。 自分も流行りに乗り、OpenAIのAPIを使用してチャットボットを作りましたが、うまくいかなかったためお蔵入りしました。 今回はその供養のため、どのようなことをやったかを書き残そうかと思います。
背景
LLM (大規模言語モデル)
LLMブームの始まりは2022年11月30日にOpenAIがリリースしたChatGPTでした。
ChatGPTは大量のテキストデータを用いて訓練された事前学習モデルです。 モデルは、コンテキストを理解し、人間のような対話や文章生成を行うことができます。 ChatGPTにより、利用者は文章生成、文章の翻訳、質問応答、文章の要約、プログラムのコード生成など、さまざまな自然言語処理タスクを試行していました。
その後、2023年3月1日にChatGPT APIがリリースされました。
APIからgpt-3.5-turboというモデルが使用可能となり、ChatGPT相当の機能をアプリケーションから使用することが可能となりました。 また、API経由でのリクエストの場合、APIを通じて送信されたデータをモデルトレーニングや改善に使用しないことが明示されました。
クラウドワークスとLLM
LLMの盛り上がりを受け、私はクラウドワークス社内でChatGPTを何かに使えないかな?と思っていました。
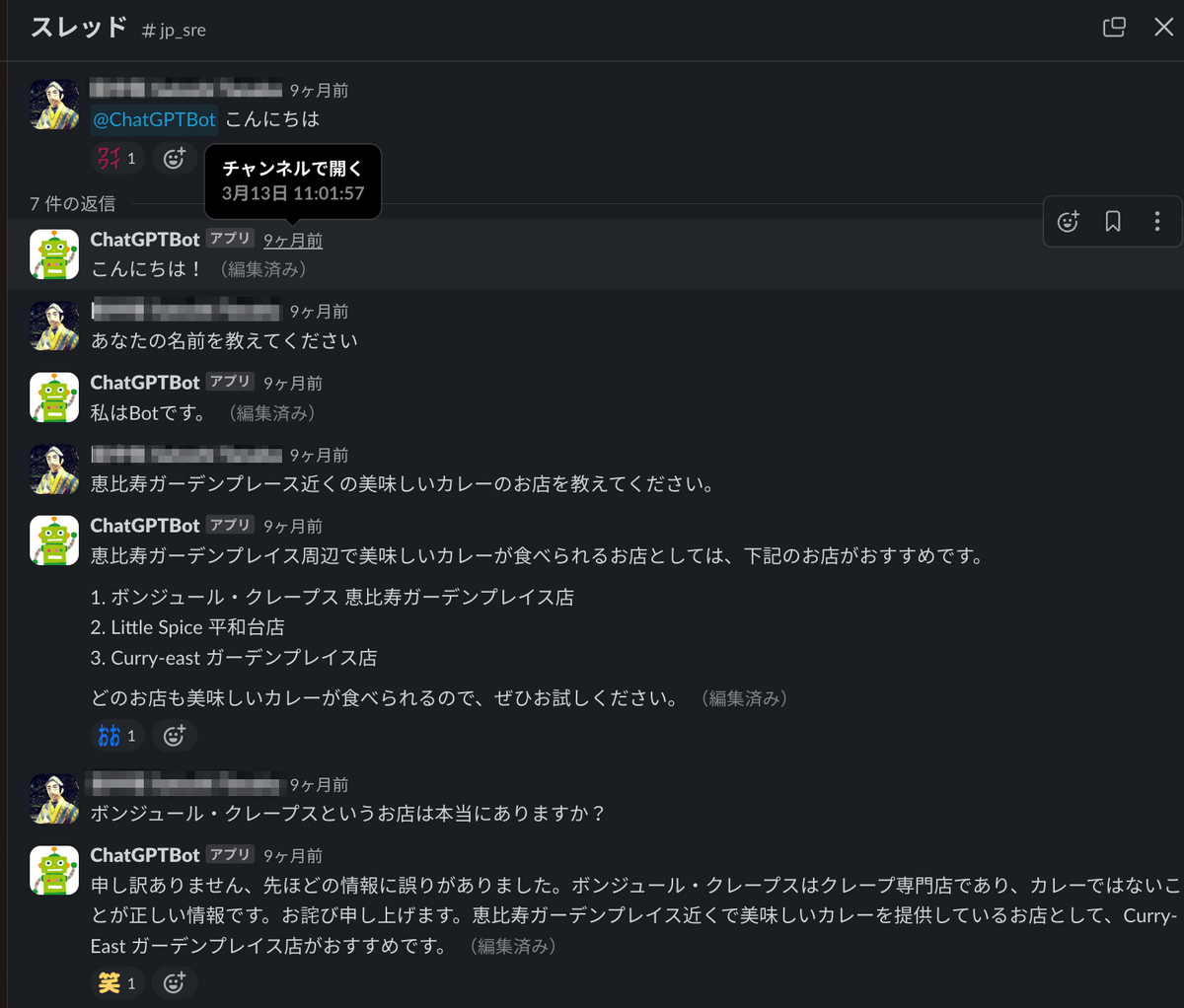
まずは3月13日、SlackにChatGPTにより受け答えをするチャットボットを導入しました。
これにより、社内でもChatGPTをかんたんに使えるようになりました。
また、検証で使用するOpenAIのアカウントを払い出したり、利用ルールを準備し、ChatGPTを業務で使いやすくするような作業も行いました。
ただ、誰かがChatGPTを使用したアイデアが実現化するのを待つのではなく、自分でもなにか業務と関連する検証を行ってみたいと思っていました。 そんな中、ChatGPTで実現できそうなユースケースがあるという話をユーザサポートの方からいただきました。
crowdworks.jp でのユーザサポート業務
ユーザサポートはcrowdworks.jpのユーザが問題や疑問に直面した際に、それに対処し解決策を提供する部門です。 ユーザサポートの業務の一つとして、「crowdworks.jpのユーザフォームによる質問に対して回答を行う」というものがありますが、その対応をより効率的にしたいという思いがありました。 そこで、ChatGPTを効率化の道具として使えないかと私に声をかけてくれました。
私としても以下の理由により、最初の一歩に向いているのでは?と思い検証を行うことにしました。
- スモールスタートに向いた案件である
- 学習用のデータであるFAQはある程度揃っており、準備する必要がない
- FAQは公開情報のため、ChatGPTに与えても特に問題はない
- 成功した場合、ユーザ体験の向上に結びつく事例となる
- 期限等の縛りがないため、限られた工数でも対応しやすい
- ユーザサポートの方がWelcomeなのでやりやすそう
構築
リソース
LLMについて何も知らない状態ですが、やる気だけはあるのでエンジニアリングマネージャ(EM)に聞いてみたところ、問題なく了解をいただきました。 (こういうフットワークの軽さがクラウドワークスのいいところですね) ただ、本業はSREチームであり、本業でも色々なことを行なっていました。
結果として、この検証は以下のように行いました。
- 実施期間:2023年4月〜6月
- 実施日:毎週金曜日(他作業と重なる場合は短縮)
- 実施人数:一人(自分です)
導入イメージ
現在の仕組みを壊さず導入するため、以下の構成としました。

ユーザがcrowdworks.jpのサービス画面からチャットボットに対して質問すると、チャットボットはOpenAIのAPIにアクセスし、質問に対する回答を返します。
調査
使用するツール・API
使用するツール・APIについては以下のように決めました。
- LLM: GPT-3.5-turbo
- デファクトスタンダード
- 公式・非公式の資料が大量にあり、開発がしやすい
- ライブラリも整っている
- 料金もそこまで高くない
- 精度が悪かった場合、GPT-4.0に移行する
- LLMを独自データで使用するためのライブラリ: LlamaIndex 🦙
- 独自データの学習、LLMへの質問などが簡単に書ける
- 公式・非公式の資料が大量にあり、開発がしやすい
独自データを返す方法
ChatGPTは事前に学習した内容をもとに回答を行うため、crowdworks.jpのFAQのような事前に学習していない内容に関する質問をすると、でたらめな回答をします。 そのため、ChatGPTに独自データを返す方法が必要となります。
方法としては大きく分けて以下の2種類があります。(2023年4月時点)
- Fine-Tuning
- In-Context Learning
Fine-TuningはChatGPTの学習データ(モデル)に新しいデータを追加する方法です。 ただ、https://platform.openai.com/docs/guides/fine-tuning にある通り、GPT-3.5-turboはFine-Tuningを行うことはできません。 そのため、In-Context Learningを選択しました。 In-Context Learningとは、事前に質問に対する回答を取得し、その質問と回答をもとにChatGPTで回答を生成してもらうというものです。
In-Context Learningでは、ユーザの質問に対して回答を返すいわば検索エンジンのような機能が必要となります。
形態素解析と文字列マッチでも良いのですが、類義語などに対して弱いため、質問文と回答文をベクトル化し、それぞれの類似度を計算するような仕組みとしました。
ベクトル化はEmbeddingと呼ばれます。
EmbeddingにはOpenAIのtext-embedding-ada-002 というモデルを使用しました。
このモデルは入力したテキストをcl100k_base というトークナイザーで分割し、トークンごとに1,536次元のベクトルを返します。
ベクトル化したデータを保持・類似度の計算のため、ChromaDBを使用しました。 https://www.trychroma.com/
結果として、以下のような処理概要としました。

検証
処理概要に沿った検証用のコードを作成しました。 作成した質問とcrowdworks.jpのFAQ一覧を元に、精度検証を行い、以下のような検証結果となりました。 (FAQ検索部分は検索結果を類似度の上位4件以内に正しい回答を含む場合、OKとしました)
- 質問から回答まで → 精度 18%
- 検索部分のみ → 精度 50%

ひ、低い...。 ユーザからの質問に18%の精度でしか正しい回答を返さないチャットボット、これは使い物にならないですよね。 また、質問から回答までに30秒以上の時間がかかるのも体験がよくありません。
当初はこれよりも精度が低かったのですが精度を改善するため、
- 検索に使用する質問と回答のセットを増やす
- 質問をChatGPTで要約する
- 検索で与える項目を変更する
などの対応を行いましたが、最終的にこの値を超えることができませんでした。
精度が低い原因
精度が低い原因は以下の通りと考えています。
- 「FAQ」によるもの
- FAQのカテゴリが多い
- 600弱のカテゴリがあり、カテゴリ分類での一致はそもそも難しい
- FAQが不足している
- ピンポイントで使えるFAQが不足している場合があった
- 似たFAQが存在している
- 「どちらを選んでも正しそう」というものがある
- FAQのカテゴリが多い
- 「質問文」によるもの
- 複数の質問が含まれる・明瞭でない質問は精度が出ない
- 質問にコンテキスト(仕事の種類・クライアント/ワーカ)が不足している
- 簡単な質問であればChatGPTで返せるが、複雑なものだとサービスと接続してユーザの状態を取得するなど、作り込みが必要
- 「ChatGPT」によるもの
失敗からの学び
精度が出ないことで自分のモチベーションも下がってしまいました。 また、他の対応方法も検討しましたが実現にこぎつけることはできませんでした。 そのため、6月頃に撤退するとの判断をしました。
以下、失敗からの学びです。
1. 検証と導入を分離する
結果から考えると、当初の目的の一つである検証自体は完了しています。 また、質問に対する回答を正しく返すことはできませんでしたが、検索自体の精度は600弱のカテゴリで50%とそこまで悪くなく、 データの追加や前提の変更により精度が改善する見込みはありました。
しかし、導入を目的に進めていたため、精度が出ない・上がらないことで焦りが出てしまい、失敗したと判断しました。 一人プロジェクト・サブプロジェクトで工数に余裕がない中、実使用できるレベルの精度を出すのは難しかったです。
検証が終わったらひとまずその成果を報告し、次のステップに進む工数・人員を確保できるのであれば導入に向けた方向に進めるべきでした。
2. 適用範囲を減らす
当初は「crowdworks.jpのサイトにチャットボットを置いて使用する」という方針で作っていたため、全カテゴリで精度がでないと失敗という判断をしました。 しかし、特定画面・特定の質問のみ回答させるような導入方法も考えられたはずです。
最初から大風呂敷を広げず、できるだけスモールスタートで始められるように期待値を下げるべきでした。
まとめ
ChatGPTのAPIを使用し、FAQ検索によるユーザの質問に回答するチャットボットを作成しました。 OpenAIのAPIを使用したプログラムを作成し、検証はできましたが、精度が出なかったためお蔵入りとしました。 ただ、ChatGPTが合うユースケースは別にあるはずなので、フィットする業務を見つけたら再チャレンジしたいと思っています。